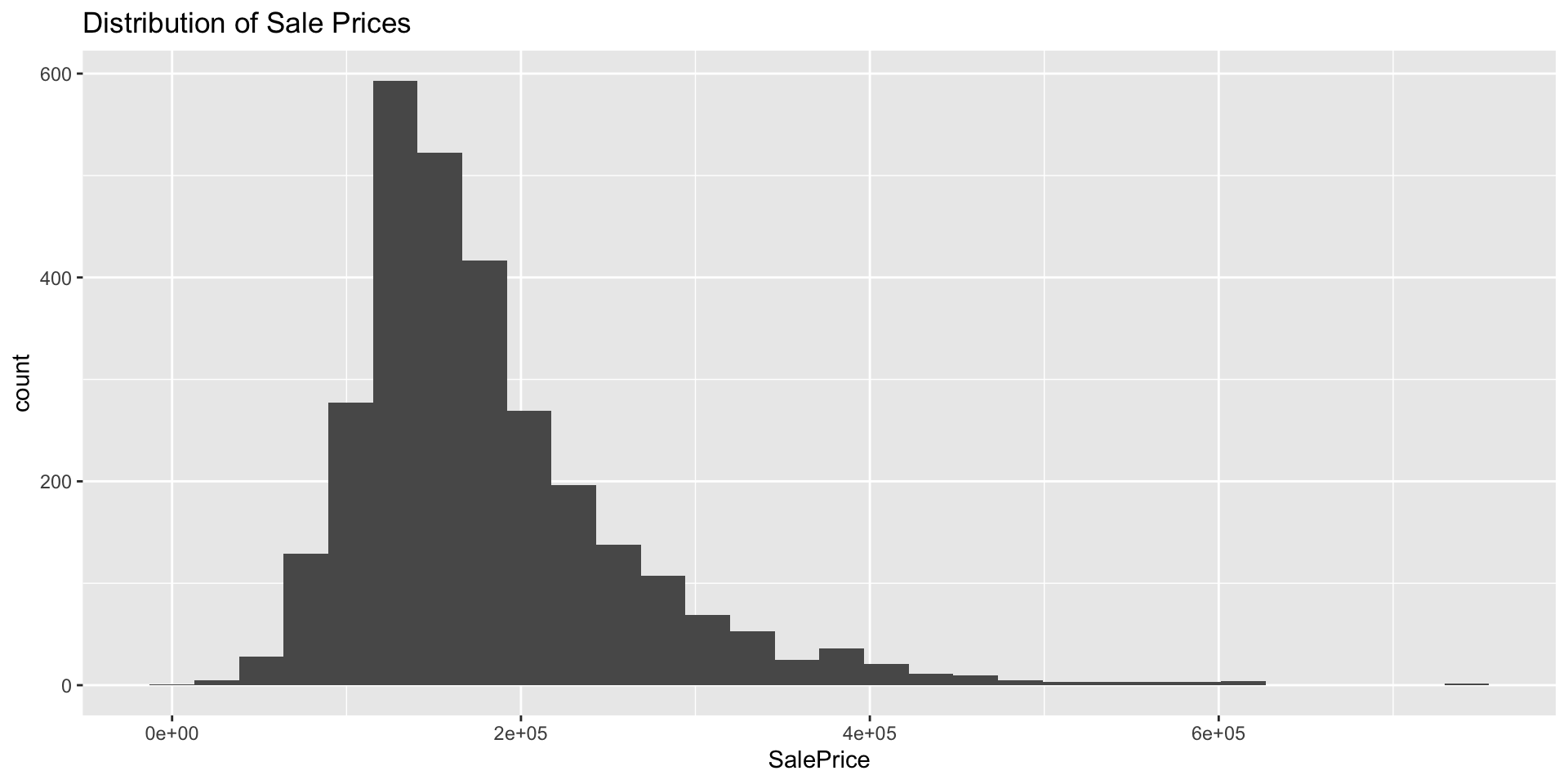
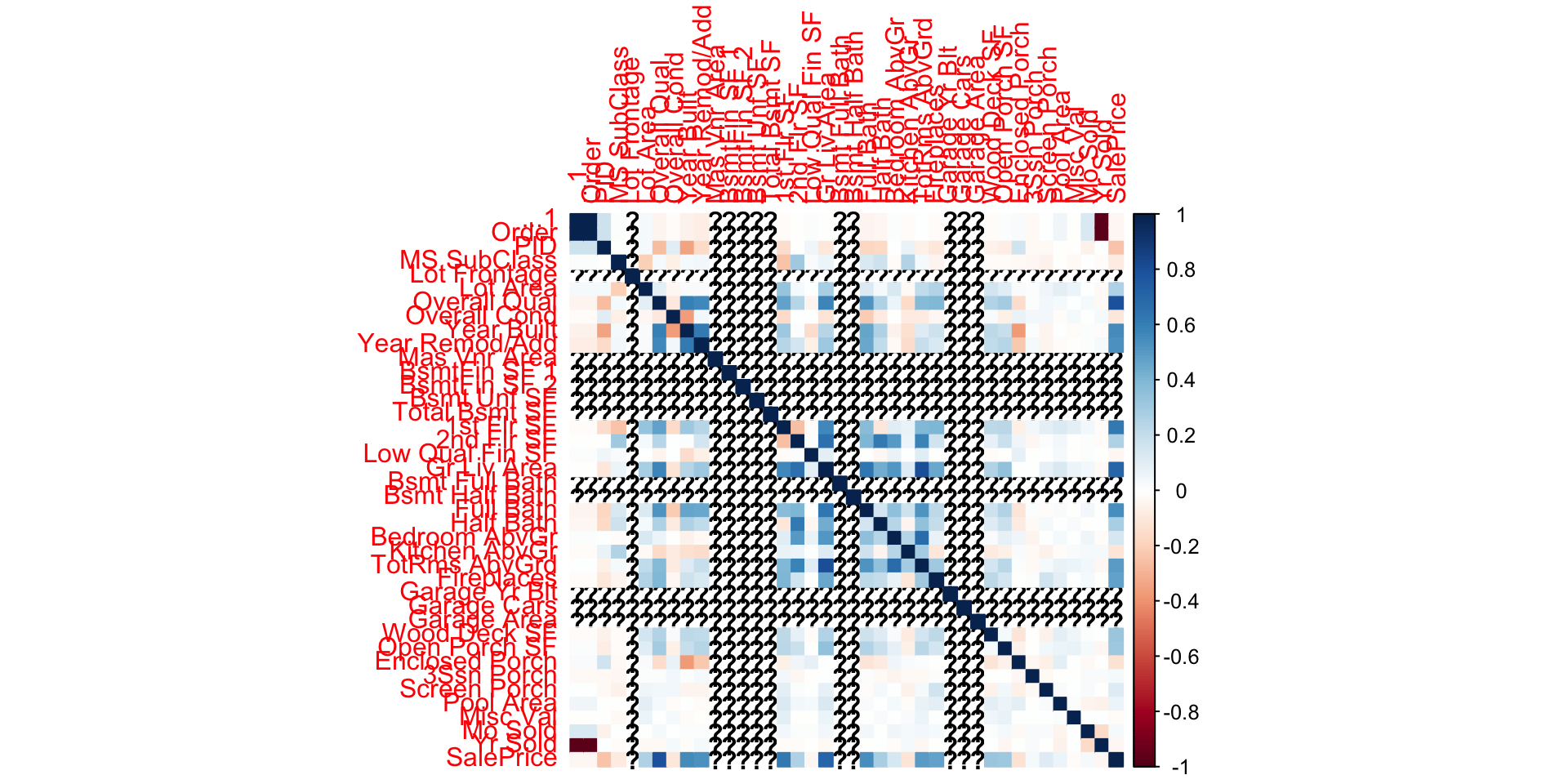
# A tibble: 6 × 83
...1 Order PID `MS SubClass` `MS Zoning` `Lot Frontage` `Lot Area` Street
<dbl> <dbl> <dbl> <dbl> <chr> <dbl> <dbl> <chr>
1 0 1 5.26e8 20 RL 141 31770 Pave
2 1 2 5.26e8 20 RH 80 11622 Pave
3 2 3 5.26e8 20 RL 81 14267 Pave
4 3 4 5.26e8 20 RL 93 11160 Pave
5 4 5 5.27e8 60 RL 74 13830 Pave
6 5 6 5.27e8 60 RL 78 9978 Pave
# … with 75 more variables: Alley <chr>, Lot Shape <chr>, Land Contour <chr>,
# Utilities <chr>, Lot Config <chr>, Land Slope <chr>, Neighborhood <chr>,
# Condition 1 <chr>, Condition 2 <chr>, Bldg Type <chr>, House Style <chr>,
# Overall Qual <dbl>, Overall Cond <dbl>, Year Built <dbl>,
# Year Remod/Add <dbl>, Roof Style <chr>, Roof Matl <chr>,
# Exterior 1st <chr>, Exterior 2nd <chr>, Mas Vnr Type <chr>,
# Mas Vnr Area <dbl>, Exter Qual <chr>, Exter Cond <chr>, Foundation <chr>, …